伴随着大数据技术的兴起,经常听到使用列式存储的数据库性能高的说法,今天就来一探究竟,待解决的疑问主要有:
- 什么是行式存储和列式存储
- 是否在任何情况下列式存储都比行式存储性能高
行式存储
典型的关系型数据库中,每个行是一条记录。使用行式存储,那么每一行的数据依次顺序存储在磁盘上。
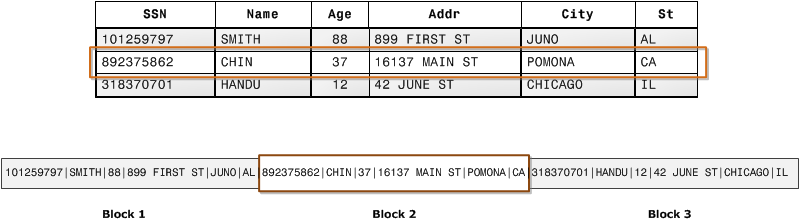
数据库按指定大小的数据块来存储表数据和索引,如果一行记录的数据大小大于数据库的数据块大小,那么一行记录就要使用多个数据块。反之,一个数据块写入一行记录后还有空余空间——从而造成了浪费。
读写
先看写操作,添加记录的时候文件系统可以直接在当前数据后添加,效率很高。当要修改某条记录时,需要读取某行记录对应的数据块,然后进行更新。而在查询的时候(不考虑索引的情况下),数据需要整行读取,然后选取目标列。如果是聚合运算的时候,比如 sum 或 max 操作,需要将所有相关行的内容读取到,再逐行解析出目标列的值,再进行运算。从操作和运行时所需的内存来看,效率偏低。
(暂时不考虑删除的情况,因为不同的数据库在实现删除的时候,有不同的实现。)
列式存储
列式存储将每个列的数据存储到数据块上,也就是说一个数据块上包含的是同一列的多行数据。
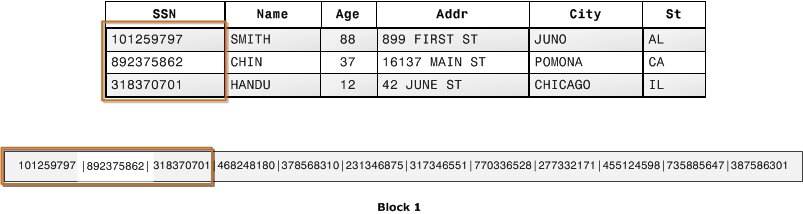
读写
对于写操作,需要将每行的数据按列拆分再进行存储,这无疑比行式存储的效率低。当有更新的时候,也是类似,需要更新N列,就至少有N次读数据块操作。而在查询的时候,可以只读取需要的目标列,数据不存在冗余。对于聚合运算,效率无疑就更高了。
此外,当列中出现的数据重复率很高时,就可以进行压缩,从而进一步减少存储空间和磁盘I/O次数。
总结
通过对两种存储方式的理解,可以得到的结论是:
- 在聚合运算多的场合,列式存储占优
- 在写操作多的场合,行式存储占优
Comments